The Perceptron Learning Algorithm (PLA) is a principled way of learning the weights assigned to the input points such that the error between the prediction made the Perceptron model and the actual label of the inputs is minimal. Convergence is said to have occurred when all the points are classified correctly. The following screenshot explains the algorithm in pseudocode:

is the input vector and is the weight vector . The algorithm says that if we have a positive point, which is incorrectly classified as negative, we must add that point to the weight vector. Similarly, negative points wrongly classified as positive must be subtracted from the weight vector. The perceptron algorithm states that:
is basically the dot product of the weight vector and input vector: . Hence we are interested in finding the plane which neatly divides the input space into two halves. All points that lie on this line are perpendicular to the weight vector since .
Points that lie on the positive half-space of the input space (i.e., ) form an angle less than with the weight vector while those in the negative half-space form an angle less than . The following figure demonstrates this:
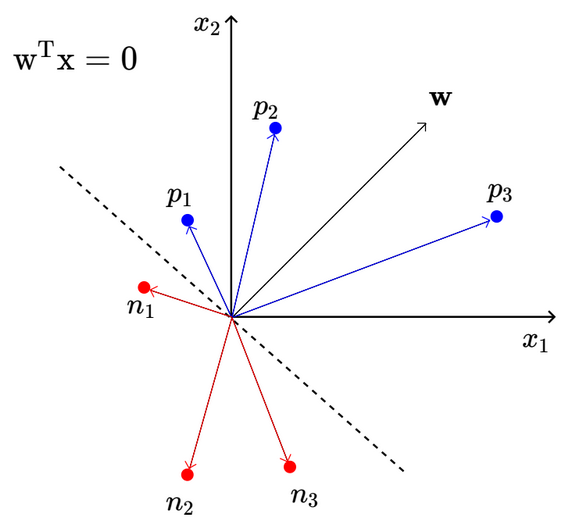
represent the points in the positive half-space while are the points in the negative half-space. This means that positive points that are misclassified form an angle greater than with the current weight vector, but we want it to be less. As per the algorithm, if a positive point is misclassified, we add it to the weight vector, forming . Therefore:
Hence, . This shows that upon adding the point to the weight vector, the angle it forms with the weight vector, now updated, is less than what it was. It may not be possible to bring the angle below in one shot but inches us closer to that goal. Naturally, the same logic would apply if a negative point is misclassified, meaning that the angle it forms with the weight vector is less than what we’d like it to be. We subtract such a point from the weight vector.
This shows us that updating the weight vector according to the above method could make the algorithm converge. However, since we’re picking input values at random and updating the weight vector based on their state, how do we know that the algorithm won’t keep flip-flopping between different values infinitely? For example, one input element could add to the weight vector but the next could subtract from it and bring it back to the previous value and this could go on forever.