Till now, we have focused entirely on linearly separable functions since single Perceptrons cannot implement functions that aren’t separable. Most functions in the real world aren’t linearly separable and we therefore need a model to deal with them. A network of Perceptrons, as opposed to a single one, could do the trick. One such inseparable function is the XOR function.
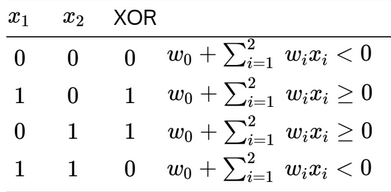
From the table, we derive the following set of inequalities:
- The fourth inequality contradicts the second and third, meaning that isn’t a linearly separable function.
If we have 2 inputs, how many Boolean functions can we create with them? Since there are 4 possible inputs - there are possible 16 combinations of outputs. This generalises to for inputs. Of these functions, the number of them that are linearly separable is hard to tell.
Getting back to dealing with linearly inseparable functions, let’s assume and a network of Perceptrons, each of which is connected to both the inputs with specific weights, either 1 or -1, which are hard-coded. The bias is assumed to be and the output of this network is either or . The output of each perceptron in the network is and these outputs are assigned weights which need to be learned.
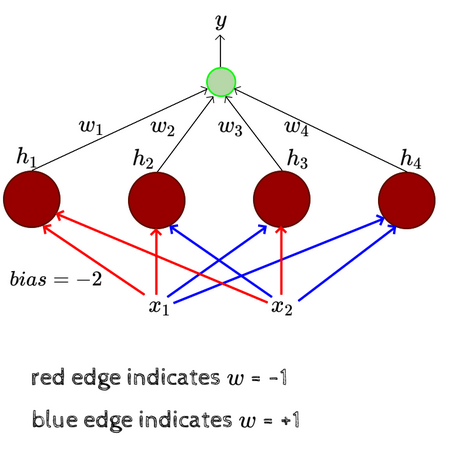 This network contains 3 layers:
This network contains 3 layers:
- The layer that contains the inputs is the input layer.
- The layer with the 4 perceptrons is the hidden layer.
- The layer containing the output neuron is the output layer.
to are the outputs of the perceptrons in the hidden layer. The red and blue edges are called layer 1 weights while to are called layer 2 weights. Note that the layer 1 weights are hard-coded and assigned purposefully. The layer 2 weights, on the other hand, need to be learned. This network can be used to learn any Boolean function, regardless of whether it’s linearly separable.
If we take a close look at how the layer 1 weights are assigned, we see that each perceptron in the hidden layer fires only for a particular input. Let’s take the input . The weighted sum of the first perceptron will be which is greater than and will hence fire. For the second perceptron the weighted sum will be which is less than and will not fire. Looking at each of the four possible inputs and computing the weighted sum for each perceptron, we notice that only one of the perceptrons in the hidden layer will fire, as long as we engineer the layer 1 weights in a particular manner.
If is the bias assigned to the hidden layer, the output will be if else . In the above example, the input ) meant that only the first perceptron in the hidden layer fired, meaning that since . All the other h’s are 0. For other inputs, each of the other 3 perceptrons would fire and the weighted sum will be the respective weight. Now, if we look at the XOR function with such a network, it can be implemented:
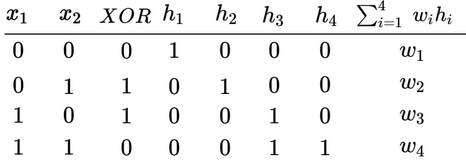
- 0 should be replaced by -1.
Each is responsible for one of the four possible inputs. If we write out the set of inequalities, there won’t be any contradictions, meaning that the function can be implemented.
Such a network can be used to implement all the other possible boolean function as well and can be used for any number of inputs. However, the catch is that as starts to grow, the number of perceptrons in the hidden layer increases exponentially.