Having established an environment for conducting supervised ML, let’s assume a simple case where there’s only one input whose weight is and bias which will be referred to as from here on. If we continue using the sigmoid function to approximate the relationship between the input and output of the training data, we have the following setup:
If we have input-output pairs in the training data, find and such that the loss is minimal. The loss function, in turn, is:
The brute-force way to go about doing this would be to randomly guess several different combination of and and see which one returns the least loss. If we have 2 input-output pairs and , here are some possible values for and along with their respectives losses:
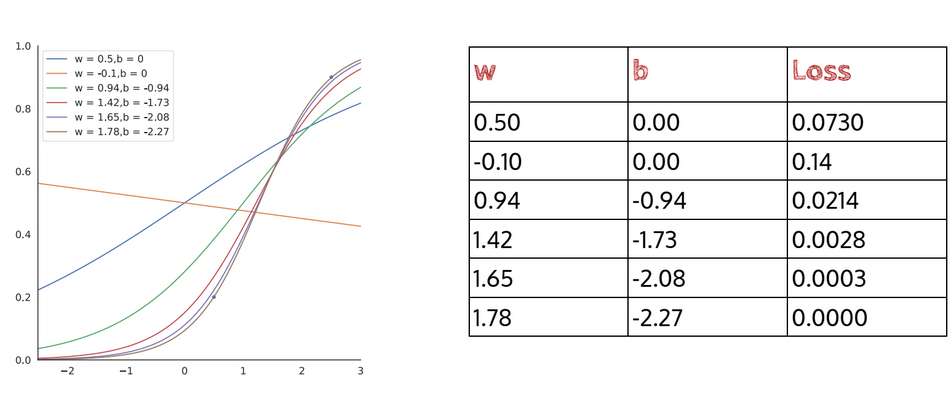
Another possible way is to conduct a random search on the error surface, which is a visual way of going about this task:
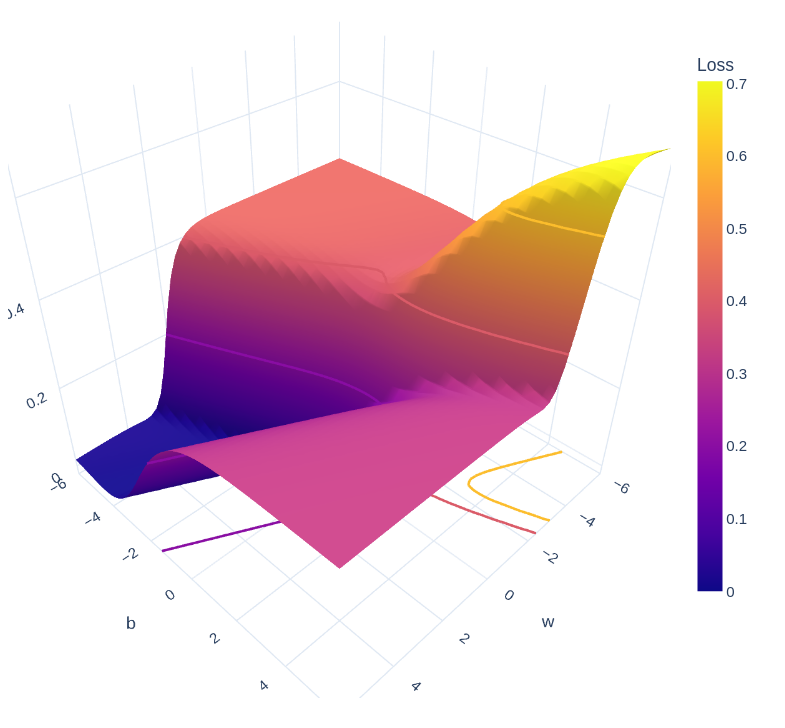
Needless to say, neither of these methods is optimal since they are completely based on guess work.