Feedforward neural networks are defined by DeepAI as:
A feedforward neural network is one of the simplest types of artificial neural networks devised. In this network, the information moves in only one direction—forward—from the input nodes, through the hidden nodes (if any), and to the output nodes.
The input to such a network is an -dimensional vector. The network contains layers with hidden layers and one output layer. The input layer is considered to be the layer. Let’s assume that each hidden layer consists of neurons and the output layer has neurons.
Each neurons in the hidden layers and the output layer consists of a pre-activation part and an activation part . Each input has a weight to every neuron in the first hidden. Similarly, every neuron in each hidden layer has a weight to each neuron in the layer coming after it. Each neuron in each layer has a bias attached to it too. This setup is represented by the following diagram:
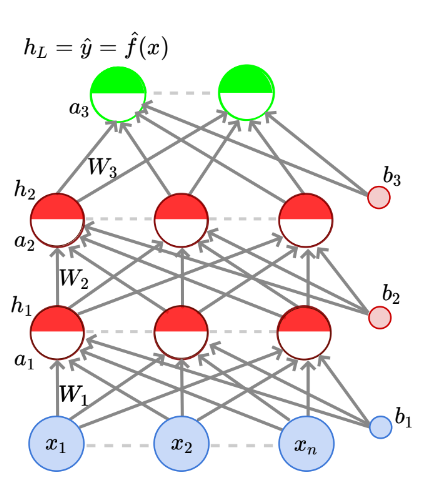
Putting all the input variables together, we get the input vector . Each neuron of a hidden layer has weights (for each neuron/input from the previous layer). If combine the weight vectors for all the neurons in a particular layer, we get an matrix. Hence, . Similarly, since each neuron in a layer has a bias, the bias vector for the entire layer is in i.e., .
The pre-activation part of each neuron takes the weighted sum of the outputs from the previous layer and adds the bias to it. Remember that all these computations are done with vectors since bring all inputs, weights and biases into its respective vectors. The calculation of the activation for the first hidden layer, assuming would be:
- For the second hidden layer onwards, should be replaced by .
Writing the above in a generic form, we get:
The activation part of the neuron takes the pre-activation part’s output and applies a function on it. This function could logistic, tanh, linear, among others.
- is called the activation function.
The activation in the output layer, which uses different notation is:
Using the manner in which supervised learning setups are typically represented, we can represent this situation in the following manner:
Data:
Model:
- This is just how the compuation would look like if we wrote out the calculations for each hidden layer together.
Parameters:
Algorithm: Gradient Descent with backpropagation (covered soon)
Loss function:
- This takes the squared sum of the difference between the predicted output and the real output and then average the squared error for all points in the training data.