The choice of output and loss functions for a feedforward neural network depends on the nature of the problem at hand.
Let’s say we have a Regression problem, which seeks to predict the IMDB and Letterboxd rating for a movie, with 2 inputs variables - whether the movie has a good plot and if its dialogues are good:
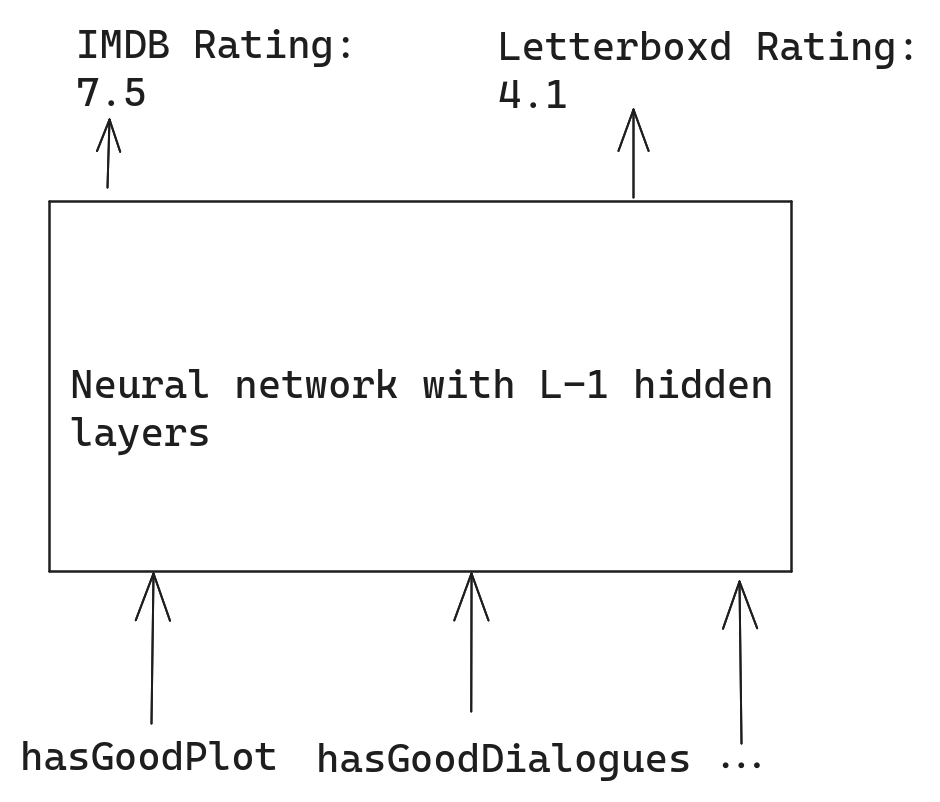
This means that and . The loss function should capture how much our prediction differs from the actual output . In this case, the squared error would work:
But before that, what should the output function be? In other words, what function should be applied to the pre-activation part of the output layer of the network. In this case, since we don’t the output to be bound between 0 and 1, a linear function would be better than the sigmoid function.
What about Classification problems?
Let’s say we have an image of a fruit and we’d like to predict whether it’s a Mango, Orange, Apple or Banana. Here, but among the 4 positions in the vector, only one of them will be 1 and the rest will be 0 since the image can only represent one fruit.
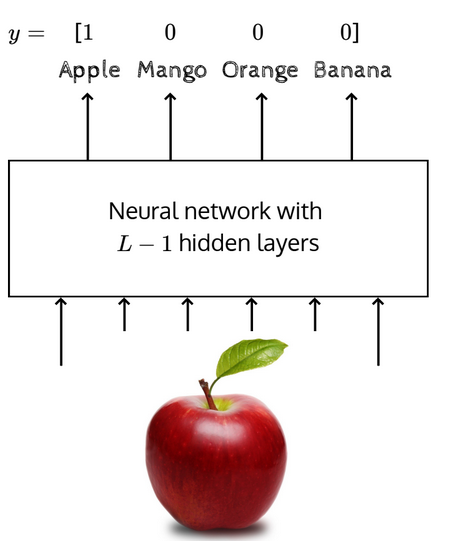
In classification tasks, we try to predict the probability of the various possible outputs. Hence, the output function should be one that ensure that our prediction vector is a probability distribution. The softmax function is one such function:
- Where is the element of and is the element of the vector .
Since and are probability distributions, we can use the cross-entropy function to compute the loss. Here are two excellent videos that explain what the concept of entropy is and why it is applicable in this context:
- Prof. Mithesh Khapra - Entropy, Information Content and Cross-Entropy
- Statquest - Entropy (for data science) Clearly Explained
The cross-entropy function is:
In the true output vector, one element is 1 and the rest are zero, meaning that for each is either 1 or 0, this means that the loss function can be simplified as:
- Where represents that probability assigned to the true class label. For example, if we have an image of an Apple, would be 1 for it and 0 for all other fruits and the loss function would only the probability of an Apple into consideration.
Minimizing the above is the same as maximizing the negative of it. So, the loss function can be rewritten as:
- This quantity is known as the log-likelihood of the data.
So far, we’ve seen functions with two kinds of outputs - real values and probabilities. The type of output and loss function used in both contexts are given in the table below:
| Real Values | Probabilities | |
|---|---|---|
| Output Function | Linear | Softmax |
| Loss Function | Squared Error | Cross-Entropy |