After examining the roles that the output layer and hidden layers play in the performance of a model, we now turn to the parameters (i.e., weights and biases) and look at their culpability.
Let’s look at the weights first:
In the RHS, we need to compute 2 partial derivatives. We know the result of the first one from the previous section. As for the second part, remember that . If we differentiate this with respect to the weight, we’re left with just the activation output from the previous layer.
i.e., the weights for a particular layer is a matrix and not a vector. This matrix would look like:
Let’s assume that . In that case, the weight matrix would be (shamelessly taking a screenshot since I’m too lazy to type it out on my own):
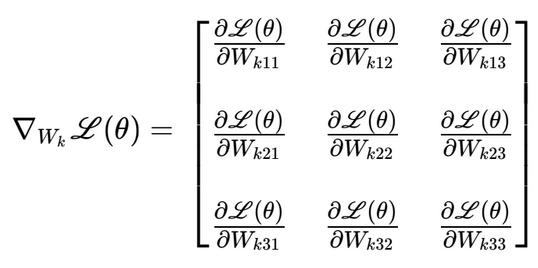
Applying the formula derived above to this matrix, we get:
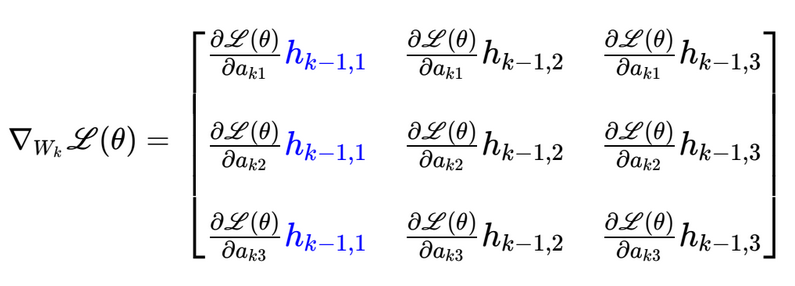
This matrix is just the outer product of the gradient of the loss function with respect to and the activation output of the layer:
Looking at the bias, remember once again that . This means that if we differentiate the loss function with respect to the bias, we get:
Hence, the gradient vector would be: