Now that we have looked how to calculate the gradient of the loss function with respect to the output layer, hidden layers and the parameters, we can perform the backpropagation algorithm.
Since we’re using gradient descent to optimise the weights and biases, we first initialize them randomly and set a maximum number of iterations. For each iteration, we take the outputs for each hidden layer ( and ) and the output layer () obtained from the forward propagation process. Then, we take the gradients of the parameters that were obtained from the backward propagation process. Finally, we adjust the weights by moving them in the opposite direction of the gradient.

In the forward propagation bit, we calculate outputs for each layer in the neural network based on the weights and biases. For a network with layers, the pseudocode for forward propagation is:
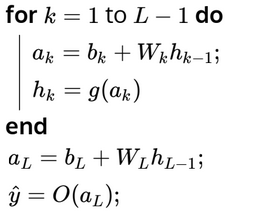
For the backward propagation process, for each layer, we first calculate the gradient of the loss function with respect to the output, then the parameters, the activation part of the layer below and finally the pre-activation part of the layer below:
