Let’s say we have neural network with several points, each of which has 4 features, and uses the sigmoid function for activation. Each point would look something like this:
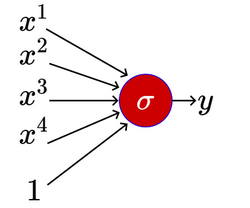
Since each feature will have a weight, the gradients of the weights will be:
For points, sum up all the gradients of each weight to get the total.
Now, what can we do if a feature is sparse - it is 0 for most points? The gradient would be 0 in most such cases meaning that it would get very few updates. If this feature is an important one, despite being sparse, we’d like to give more importance to its updates. Jacking up the learning rate for this feature alone would allow us to make larger updates to its gradient. So, how can we set different learning rates for each feature which takes care of the issue of sparsity?