Both ADAGRAD and RMSProp are both sensitive to the initial learning rate and could possibly never converge if the learning rate chosen initially is not suitable. ADADelta avoids setting an initial learning rate and instead takes the difference in gradients between iterations to update the weights. The update rule for this algorithm is:
- The effective learning rate here is instead of , which means that gets replaced by .
We can see that is a function of , which in turn is a function of past updates to the gradient, as opposed to which is a constant. This means that the numerator of the effective learning rate isn’t constant and can change depending on the gradient/slope.
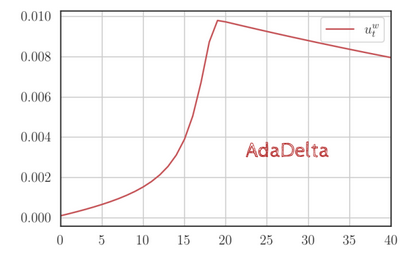
Also notice that at a particular iteration the numerator of the learning rate takes the accumulated history of gradients till the previous time step, which is why we take . This means that is one iteration behind . So how can this help in adapting the learning rate to the slope/gradient of the region we are currently in? Both and increase after each iteration, but the magnitude of is less than that of as it takes only a fraction of the squared gradient, since it’s moderated by .
In steep regions, where the gradient is high, would zoom ahead, but isn’t too far back since it’s only one iteration behind, ensuring that the effective learning wouldn’t decay as aggressively, even though increases fast.
Now, if we move to a flatter region, will reduce due to the momentum factor . However, since is behind , it would not have decreased so much, and the ratio of the numerator to the denominator would start to increase. If the gradient remains low for enough time, the learning rate would increase.
Thus, ADADELTA allows the numerator of the effective learning rate, which is kept constant in ADAGRAD and RMSProp, to vary depending on the previous gradients. The learning rate, therefore, decays slower:
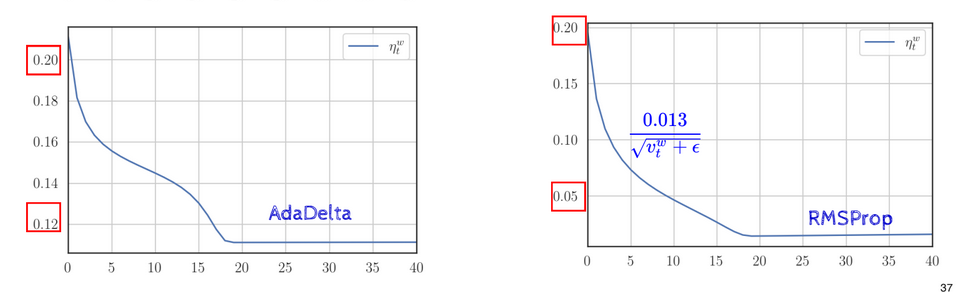
This is because of the fact that changes in proportion to , keeping its influence in check.
This compares the two, with for RMSProp and and for ADADelta. ADADelta converges faster as its learning rate doesn’t decay as quickly.