The next Gradient Descent-based algorithm we look at is Adam, which does everything RMSProp and Adadelta do to minimise the decay of the learning rate, and uses a cumulative history of the gradients. The update rule for Adam is:
- Typically, and
In the previous algorithms, the effective learning rate was multiplied by the gradient of the current iteration to update the gradient. This time, we multiply it by the cumulative history of gradients i.e .
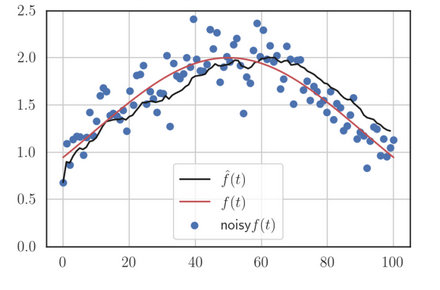
Further, and are responsible for what is called bias correction, which is why the final gradient update is done with these bias-corrected values instead of their original (biased) computations. Remember that the factor was introduced initially to create a moving average of the past and current gradients. and are usually 0, which means that if we did not bias-correct, the computations of and in future iterations, at least at the beginning, would be biased towards 0, which shouldn’t happen since there is no sanctity to the fact that they were initialised to 0. The bias correction eliminates this bias to 0. Also, without bias correction, the learning rate would be too large initially, which could lead to the minimum being overshot, as shown in this.
{kind=link}
Suppose we perform stochastic/mini-batch Gradient Descent on a dataset and the current batch doesn’t represent the data well i.e is “noisy”. The gradient computed without bias correction, the gradients would be heavily biased towards zero:
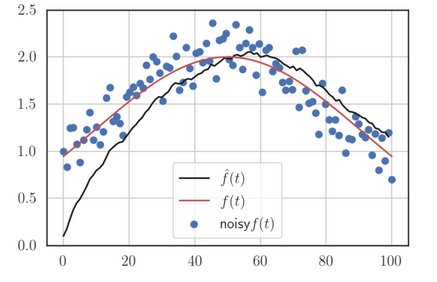
But if we apply bias-correction, the estimations would be better: