Recall that the update rule for RMSProp is:
is essentially the weighted average of the squares of all the gradients to date. If we remove the weights i.e , it is the same as calculating the norm. Instead of taking norm, we can take norm, where each current gradient would taken to the power . The norm of any vector works out to its maximum element. In the calculation of , we sum up the current gradient and past gradient. If we apply norm (also known as norm) here, would be the maximum of the current gradient and all the past gradients. The update rule for MaxProp therefore is:
- Since this a modification of RMSProp, we use a constant initial learning rate.
Unlike Adam, we don’t use bias-correction in MaxProp. Suppose and , , which means that is not biased towards zero even though it’s initialised to the same.
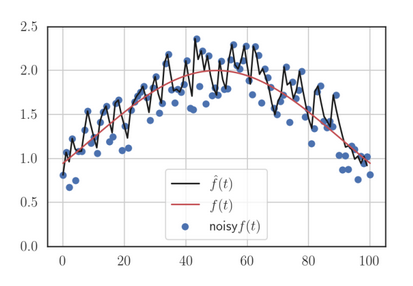
Moving on, one benefit of using the max norm instead L2 is that it keeps the learning constant when the gradient doesn’t change. This is especially relevant for sparse features. If we had used the L2 norm (RMSProp) instead, the learning rate would gradually increase (even with bias-correction), even though .
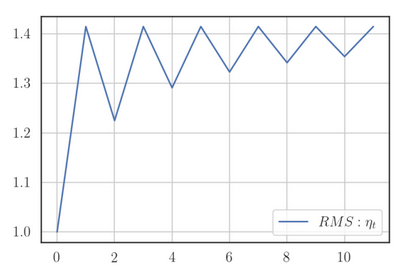
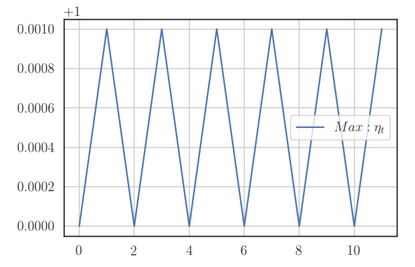
While the MaxProp algorithm modified RMSProp by taking the max norm instead of the L2 norm, we can modify the Adam algorithm in the same manner. This algorithm is called AdaMax and its update rule is:
- Notice that there is no bias correction for as it’s not susceptible to initial bias towards zero.