Using the Taylor Series, we established that changes made to the weights and bias must be in the direction opposite to that of the gradient vector. The gradient vector is the derivative of the loss function with respect to the weights and bias.
After iteration , the algorithm to update the weight at the iteration should be:
Where:
- Both derivatives are calculated at and .
The pseudocode for this algorithm is:
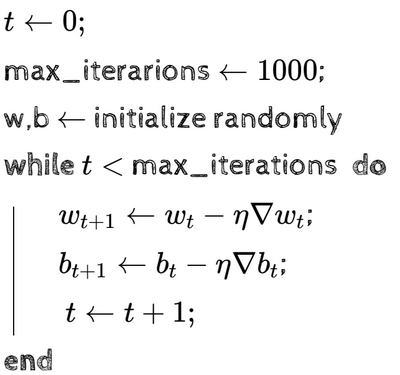
What is the formula to compute the gradient for the sigmoid function, which has been the focus till now? Remember that . Assuming there’s only one input point, the loss function is:
The derivative can therefore be calculated as:
Recall from the good ol’ days that . Using the chain rule, upon computing the derivative of the sigmoid function, we get:
Similarly:
For two or more points:
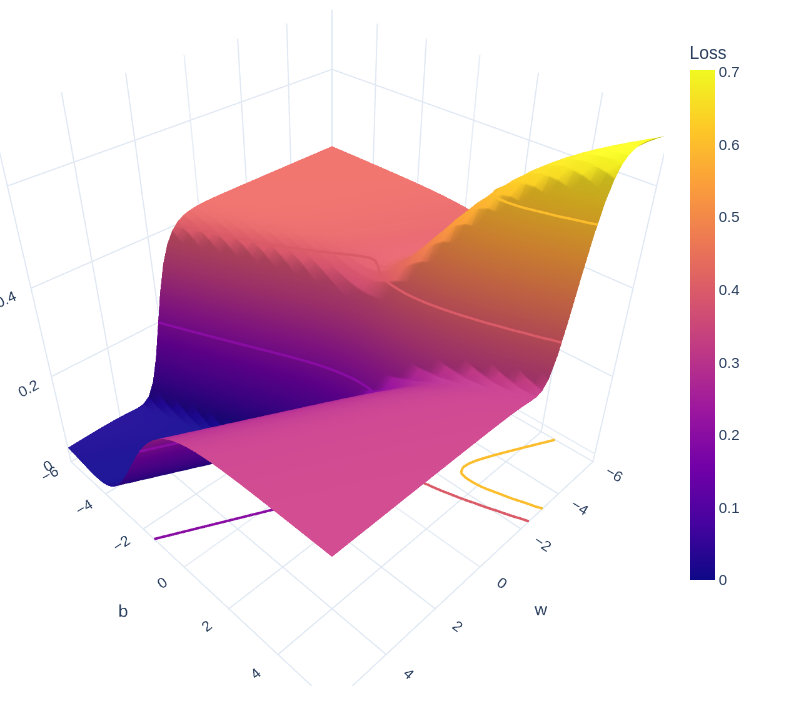
These 2 derivates can be plugged into the update formula to get the new weight vector. The following 3D plot shows the loss gradually decreasing as the weights and bias change:
Python code for the Gradient Descent Model from start to finish:
import numpy as np
# Using sigmoid function
def output(x, w, b):
return 1 / (1 + np.exp(-(w * x + b)))
def gradient_weight(x, w, b, y):
fx = output(x, w, b)
return (fx - y) * fx * (1 - fx) * x
def gradient_bias(w, x, b, y):
fx = output(x, w, b)
return (fx - y) * fx * (1 - fx)
def grad_desc(X, Y, w, b, eta, max_epochs):
weights = []
biases = []
for i in range(max_epochs):
dw = 0
db = 0
for (x, y) in zip(X, Y):
dw = gradient_weight(w, x, b, y)
db = gradient_bias(w, x, b, y)
w -= eta * dw
w -= eta * dw
b -= eta * db
return (w, b)
def mean_squared_error(X, Y, w, b):
error = 0
for x, y in zip(X, Y):
fx = output(x, w, b)
error += (y - fx) ** 2
return (error / len(X))